重慶渝樂控股企業視覺形象設計 構建品牌形象新高度
在當今競爭激烈的商業環境中,企業視覺形象設計不僅是品牌的“門面”,更是傳遞企業理念、價值觀和核心競爭力的關鍵載體。重慶渝樂控股作為一家立足于重慶、輻射全國的企業,其視覺形象設計的重要性不言而喻。本文將從企業形象策劃的角度,探討如何為重慶渝樂控股構建一套系統、專業且富有感染力的視覺形象體系。
一、核心理念與品牌定位
企業視覺形象設計的起點是明確企業的核心理念與品牌定位。重慶渝樂控股應深入分析自身業務范圍(如控股投資、產業運營等)、企業文化、目標受眾及市場環境。例如,若企業強調“創新、穩健、共贏”,視覺設計需傳達出專業可靠又不失活力的氣質。品牌定位需結合重慶的地域特色(如山水之城、開放包容),將本土元素與現代商業美學融合,形成獨特識別度。
二、視覺識別系統(VIS)構建
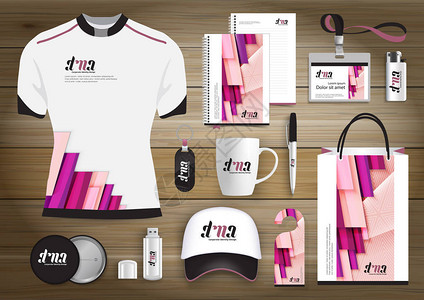
一套完整的視覺識別系統是企業形象策劃的核心,主要包括基礎要素與應用要素。
- 基礎要素設計:
- 標志(Logo):標志是企業形象的靈魂。設計應簡潔易記,可融入重慶地域符號(如長江、山巒輪廓)或“渝樂”的抽象圖形,體現控股企業的穩重與前瞻性。色彩上,可選擇深藍、金色等象征信任與品質的顏色,或加入重慶特色的“火鍋紅”作為點綴。
- 標準字體與色彩:定制專屬字體,確保在不同媒介中的一致性;建立主色與輔助色體系,增強品牌視覺凝聚力。
- 輔助圖形與IP形象:開發與標志呼應的圖案或吉祥物,提升親和力與傳播性。
- 應用要素延伸:
- 辦公事務系統:名片、信紙、文件夾等需統一設計,強化專業形象。
- 宣傳物料:海報、畫冊、網站及社交媒體視覺,應保持風格連貫,突出企業投資案例或社會貢獻。
- 環境導視系統:辦公樓、產業園區內的標識設計,需結合空間美學,體現企業規模與人文關懷。
三、文化內涵與故事性
企業視覺形象不僅是圖形組合,更應承載文化內涵。重慶渝樂控股可挖掘“渝”(重慶簡稱)與“樂”(寓意愉悅、發展)的深層含義,通過視覺敘事展現企業使命——如“扎根重慶,樂創未來”。設計中可隱含巴渝文化元素(如吊腳樓線條、兩江交匯意象),讓品牌故事更具感染力。
四、動態化與數字化適應
隨著媒體環境變化,視覺形象需具備動態化與數字化適應性。例如,設計動態Logo用于視頻宣傳,或開發簡約版標識適應移動端顯示。重慶渝樂控股可借助數字化工具(如VR展廳、交互式年報)提升視覺體驗,展現科技感與創新力。
五、實施與維護策略
企業形象策劃非一勞永逸,需長期維護與迭代。建議重慶渝樂控股設立品牌管理團隊,制定VIS使用規范手冊,定期評估設計效果并根據市場反饋優化。通過員工培訓強化內部認同,確保視覺形象從內到外統一傳遞。
重慶渝樂控股的企業視覺形象設計是一項系統工程,它根植于品牌戰略,融匯地域文化與現代美學,最終服務于企業長遠發展。通過專業策劃與創意執行,這套視覺體系將成為企業贏得信任、拓展市場的強大助力,讓“渝樂”品牌在時代浪潮中熠熠生輝。
如若轉載,請注明出處:http://www.bonabu.cn/product/45.html
更新時間:2026-06-19 05:25:28